Projects / Building a community data trust prototype
Building a community data trust prototype
A reflective walk-through of building a working community data trust prototype for Hoy and Walls.
This is the technical companion to my dissertation project on community data trusts in Hoy and Walls. The research side of the project (what I was trying to find out, what people on the islands made of it, and what I came away thinking) is written up in Tools, trust, and small places. This one is about the prototype that I built do support the research and how the choices that went into this process shaped the research in turn.
I took this project as an excuse to build a technical tool and really experience what it might be like for community organisations to build, maintain and use such data tools. It was an opportunity to design and deploy a working tool holding real peoples' data, and to think critically about it as I went. The result was a small piece of infrastructure for collecting, storing, and visualising household energy data on Hoy and Walls.
What I built
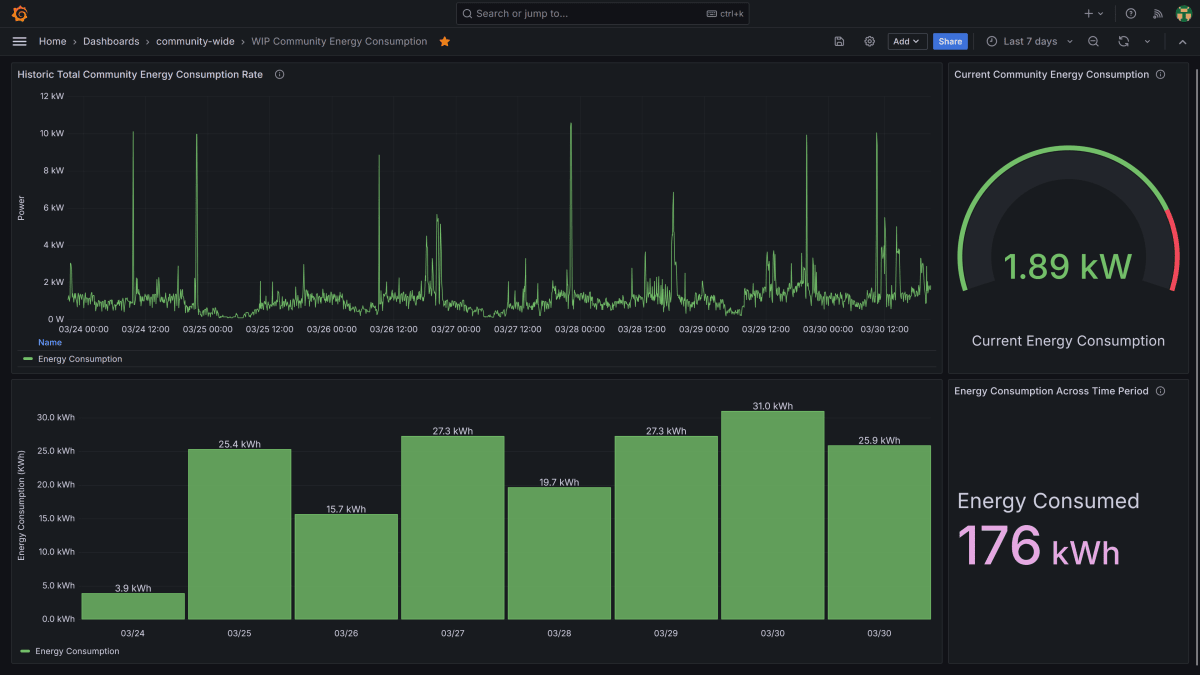
Each participant had a monitoring device installed in their meter cupboard. The device read their electricity use and sent it to Efergy's servers. From there:
- A Python script I wrote pulled the readings through Efergy's API and reformatted them.
- A TIG Stack comprised the data pipeline and analysis: Telegraf scheduled the Python script every ten seconds, InfluxDB stored the time-series data, and Grafana handled the dashboards.
- Each component sat in its own Docker container, all hosted on an EC2 box that I rented from Amazon Web Services.
- For security, I used HTTPS encryption, AWS Secrets Manager for credentials, and individual logins for participants.
Each participant could see two views: a private dashboard showing their own usage, and a shared one showing aggregated consumption across the islands.
What was hard, and what I learned
The hardest bit was the server infrastructure. I'd never set up a production environment on AWS before, and the gap between "it works on my laptop" and "it works on a server other people are logging into" turned out to be larger than I'd thought it would be. I leaned heavily on ChatGPT to get through it (this was 2024, when the models were noticeably less capable than they are now so it still wasn't easy to get this code working at all). Generative AI was genuinely useful, something in itself that is part of what I wanted to research (without that kind of support, the build would have taken much longer or stalled entirely). That tells you something about who can currently build this kind of tool, and what it takes.
How I made the choices
Every technical decision was a balance between four things:
- What's free or cheap.
- What's quickest to learn given my deadline.
- What a community member might actually choose for themselves.
- What felt ethical.
Those four didn't always pull in the same direction. Grafana, for instance, was the only tool I could find that did what I needed and had enough tutorials online for me to learn it inside the timeframe. Its dashboard modules use a query language called Flux, which I hadn't used before. I built the dashboards in it anyway, because the alternative was not building them at all. Incidentally, 2024 ChatGPT was also no good at Flux (I believe it's since been deperciated as a language) so I really had to learn a new coding language for this project.
The question running underneath
Throughout the build I kept field notes. Not just about what I was doing, but about whether a community organisation could realistically take this on – set it up, maintain it, fix it when something broke. I experienced something that I already expected: learning these skills, the trial and error and the overall design of the system take a lot of time and effort but are fundamentally achievable (as they were achievable by me, a self-taught coder). However, A tool that only its builder can maintain (and with a lot of effort at that) isn't really a community tool, however well-intentioned the build.
I'm pleased with what I made. Building a working, secure, hosted prototype from scratch is a real piece of technical work, and I enjoy this kind of making. The same skills also let me see clearly what the prototype depends on and who it shuts out. I'm grateful for this project opportunity and would love to do more critical making in this fashion in future.